项目github地址:https://github.com/hiyouga/LLaMA-Factory?tab=readme-ov-file
项目hugging face地址:
一、环境构建
1、基础虚拟环境构建
git clone https://github.com/hiyouga/LLaMA-Factory.git
conda create -n llama_factory python=3.10
conda activate llama_factory
cd LLaMA-Factory
pip install -r requirements.txt
如果要在 Windows 平台上开启量化 LoRA(QLoRA),需要安装预编译的 bitsandbytes 库, 支持 CUDA 11.1 到 12.2, 请根据您的 CUDA 版本情况选择适合的发布版本。
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
2、在虚拟环境中安装cuda、cudnn
在新建的虚拟环境中使用conda安装cuda和cudnn。
conda install cudatoolkit cudnn
安装完成后,进入python环境进行验证,检测pytorch中CUDA是否能正常使用。
import torch
torch.cuda.is_available()
如果返回True,则cuda安装正常。
如果返回False,请检查cuda和pytorch版本是否符合。
使用步骤1中的requirements.txt安装时,可能安装的是cpu版本的pytorch,使用
conda list命令查看安装的pytorch包,如果是cpu版,则需要重新安装对应cuda版本的gpu版pytorch。
进入虚拟环境中执行以下命令,安装gpu版本的pytorch,下述演示的命令安装的为适配cuda11.8版本的pytorch,请按需选择版本。
pip3 install numpy --pre torch --force-reinstall --index-url https://download.pytorch.org/whl/nightly/cu118
二、启动LLaMA Board GUI
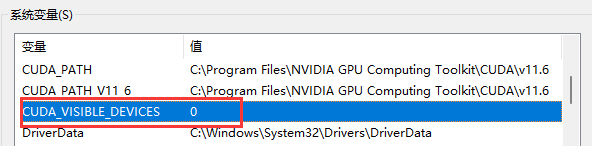
1、设置环境变量
CUDA_VISIBLE_DEVICES=0 python src/train_web.py
在Windows系统下,请设置系统环境变量CUDA_VISIBLE_DEVICES的值为0。
2、启动图形界面
再在LLaMA-Factory项目目录下使用以下命令启动图形用户界面:
python src/train_web.py

三、选择模型进行微调
1、模型选择
在LLaMA-Factory中对以下开源LLM模型进行了适配:
| 模型名 | 模型大小 | 默认模块 | Template |
|---|---|---|---|
| Baichuan2 | 7B/13B | W_pack | baichuan2 |
| BLOOM | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| BLOOMZ | 560M/1.1B/1.7B/3B/7.1B/176B | query_key_value | - |
| ChatGLM3 | 6B | query_key_value | chatglm3 |
| DeepSeek (MoE) | 7B/16B/67B | q_proj,v_proj | deepseek |
| Falcon | 7B/40B/180B | query_key_value | falcon |
| Gemma | 2B/7B | q_proj,v_proj | gemma |
| InternLM2 | 7B/20B | wqkv | intern2 |
| LLaMA | 7B/13B/33B/65B | q_proj,v_proj | - |
| LLaMA-2 | 7B/13B/70B | q_proj,v_proj | llama2 |
| Mistral | 7B | q_proj,v_proj | mistral |
| Mixtral | 8x7B | q_proj,v_proj | mistral |
| OLMo | 1B/7B | att_proj | olmo |
| Phi-1.5/2 | 1.3B/2.7B | q_proj,v_proj | - |
| Qwen | 1.8B/7B/14B/72B | c_attn | qwen |
| Qwen1.5 | 0.5B/1.8B/4B/7B/14B/72B | q_proj,v_proj | qwen |
| StarCoder2 | 3B/7B/15B | q_proj,v_proj | - |
| XVERSE | 7B/13B/65B | q_proj,v_proj | xverse |
| Yi | 6B/9B/34B | q_proj,v_proj | yi |
| Yuan | 2B/51B/102B | q_proj,v_proj | yuan |
当然,你也可以使用本地的模型进行微调。只需在模型路径中指定本地模型的文件路径即可。

2、微调方法选择
- full:对整个预训练模型进行微调,包括所有模型参数。
- freeze:只使用少部分参数进行训练,把模型的大部分参数冻结。
- lora:插入少量参数,只在新插入的参数上进行微调,达到加速效果。冻结预训练模型权重,将可训练的秩分解矩阵注入到Transformer层每个权重中。
3、训练方法选择
| 方法 | 全参数训练 | 部分参数训练 | LoRA | QLoRA |
|---|---|---|---|---|
| 预训练 | ✅ | ✅ | ✅ | ✅ |
| 指令监督微调 | ✅ | ✅ | ✅ | ✅ |
| 奖励模型训练 | ✅ | ✅ | ✅ | ✅ |
| PPO 训练 | ✅ | ✅ | ✅ | ✅ |
| DPO 训练 | ✅ | ✅ | ✅ | ✅ |
| ORPO 训练 | ✅ | ✅ | ✅ | ✅ |
请使用
--quantization_bit 4参数来启用 QLoRA 训练。
4、数据集选择
使用方法请参考 data/README_zh.md 文件。
部分数据集的使用需要确认,我们推荐使用下述命令登录您的 Hugging Face 账户。
pip install --upgrade huggingface_hub
huggingface-cli login
自定义数据集
关于数据集文件的格式,请参考 data/README_zh.md 的内容。构建自定义数据集时,既可以使用单个 .json 文件,也可以使用一个数据加载脚本和多个文件。
使用自定义数据集时,请更新 data/dataset_info.json 文件,该文件的格式请参考 data/README_zh.md。
四、模型训练
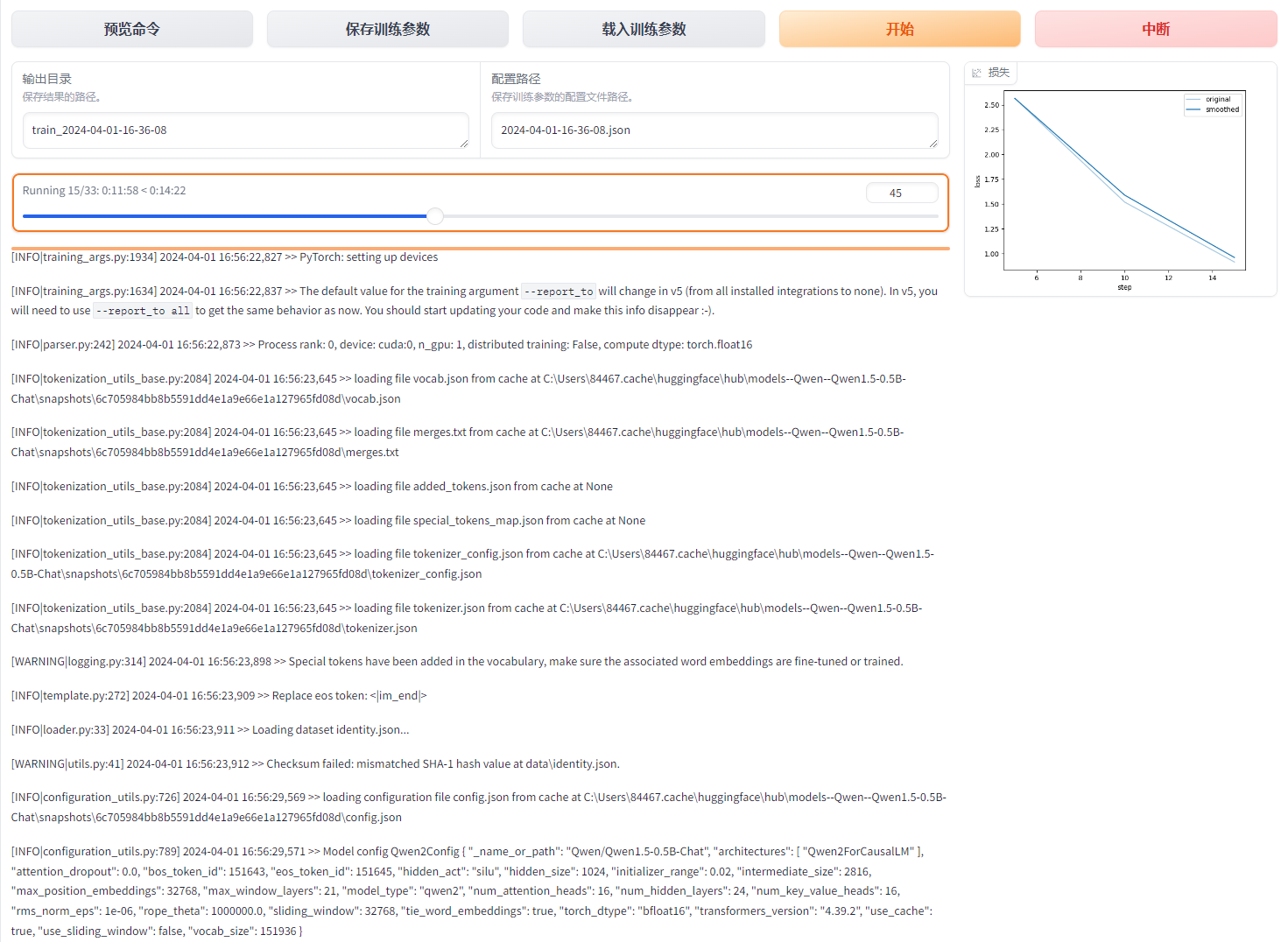
当选择好训练参数后,点击开始即可进行模型训练。
在图形界面中,可以看到训练进度、日志以及实时显示的损失值变化。
五、模型推理
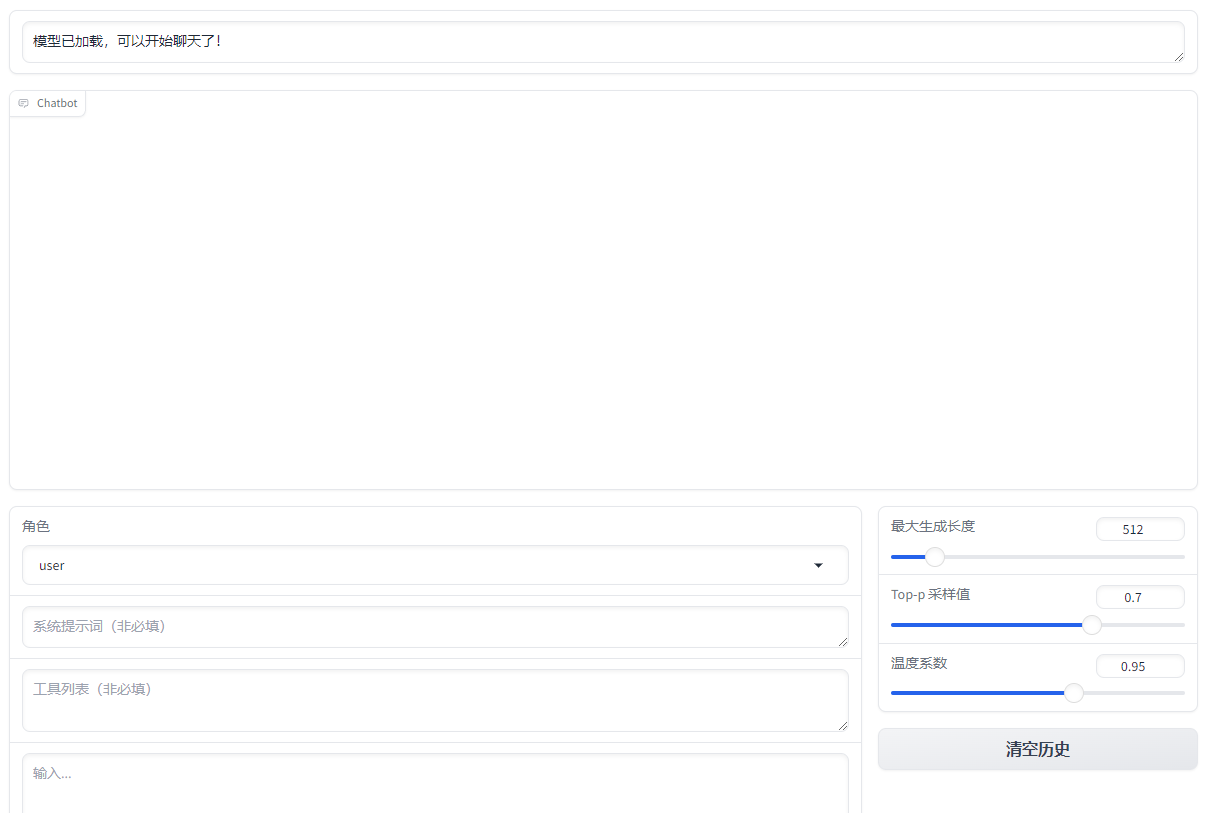
当训练完成后,点击刷新适配器,在适配器路径选择刚刚训练好的模型。

在Chat中点击加载模型。
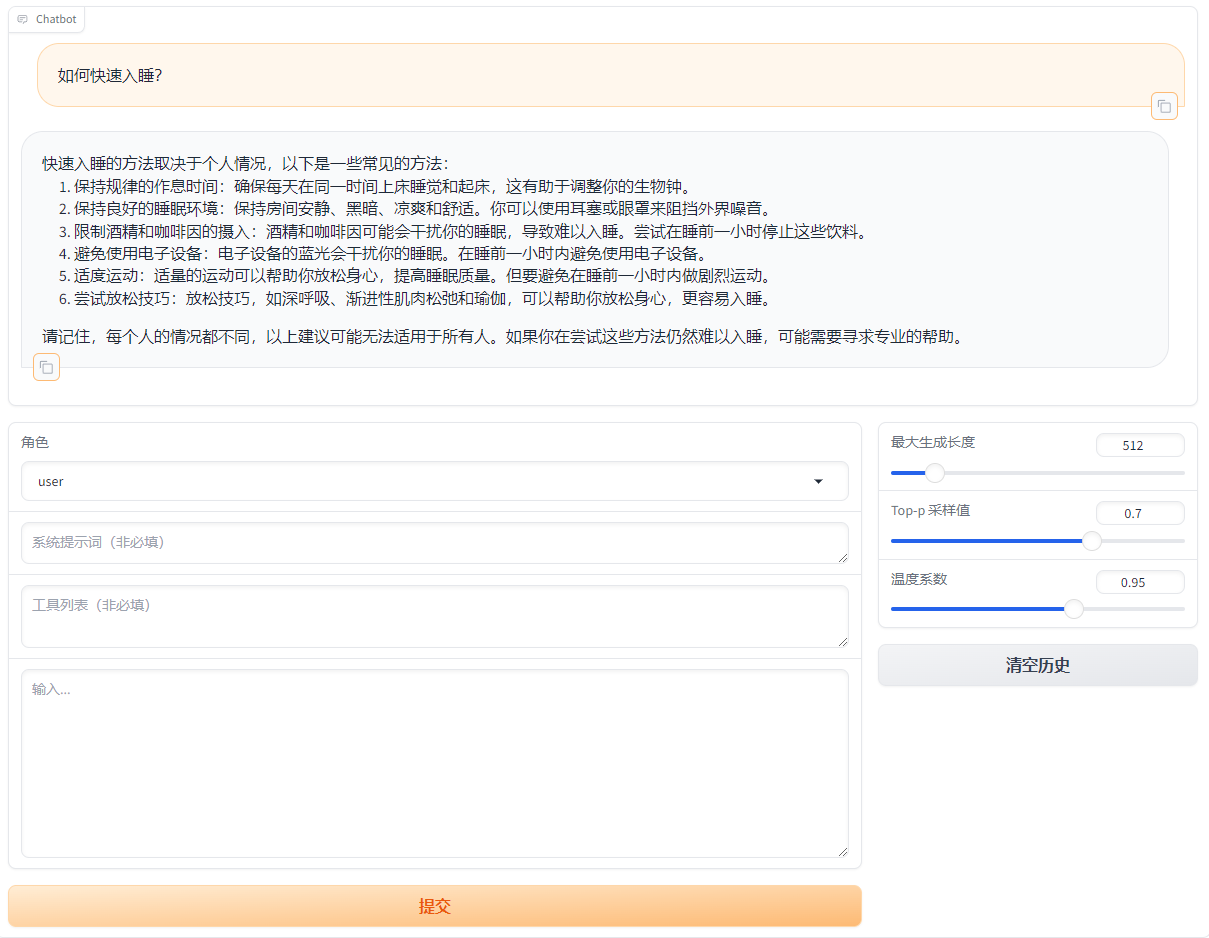
输入想要提问的问题,进行测试。